jPDFText 仕様
|
JavaアプリケーションのPDFドキュメントからテキストを抽出します

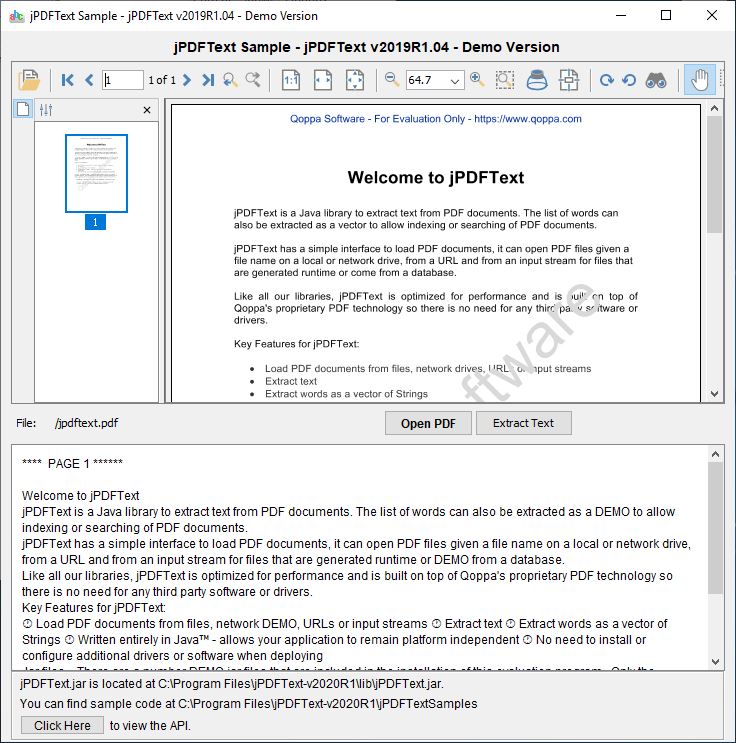
主な機能ファイル、ネットワークドライブ、URL、または入力ストリームからPDFドキュメントをロードします。論理的な読み取り順序でテキストを抽出します。文字列のベクトルとして単語を抽出します。 Windows、Linux、Unix、Mac OS X(100%Java)で動作します。展開時に追加のドライバーやソフトウェアをインストールまたは構成する必要はありません。 JDK1.4.2以降でテスト済み。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|